
В тази статия ще разгледаме накратко какви са възможностите за прогнозиране и статистически анализ с помощта на Azure Machine Learning, като за илюстрация ще изградим, обучим и използваме реален модел за анализ и класификация на произволен английски текст в 20 предефинирани категории.
Извличането на знания от данни (Data Мining) във вид на логически модели и структури/образци с помощта на статистически средства не е никак нова идея. Термини като „Data Fishing“ и „Data Dredging“ са известни още от 60-те години на XX век. Понятието „Data Mining“ добива популярност през 90-те, но теоретичните основи са поставени още през XVIII век с теоремата на Томас Бейс.
Основните класове задачи, които се решават с алгоритми за Машинно обучние / Machine Learning (Data Mining) са:
- Класификация – причисляването на даден случай/казус към една от няколко дискретни стойности – категории;
- Регресия – предвиждане/предсказване на числова (непрекъсната) стойност на изходна величина на база даден набор от входни величини;
- Клсътериране/Сегментиране – групиране на данни на малък брой подмножества използвайки най-характерните отличителни признаци. Този подклас обикновено не се нуждае от предварително обучение (unsupervised learning) и алгоритъмът сам се нагажда към данните, без да са необходими „тренировъчни“ данни;
- Асоциация – моделиране на връзки и зависимости между отделни случаи/казуси – често този подклас алгоритми се използват за т.нар. анализ „потребителска кошница“ –предложения за допълнителни продукти, които често се купуват заедно, на пакети;
- Откриване на аномалии – идентифициране на случаи/казуси, които се отклоняват значително от обичайните/средните модели/стойности.
В последните години Machine Learning технологиите навлизат и се използват във всички сфери на живота – стопански взаимоотношения, наука, технологии, медицина. Конкретни примери включват:
- анализ на риска за потребителски кредит;
- препоръка за продажба на конкретен продукт (next best offer);
- потребителска кошница – предложения за добавяне на продукти към даден продукт (cross-sell);
- откриване и предотвратяване на измами;
- прогнозиране на продажби / цени на стоки / складови наличности;
- маркетинг анализ – таргетиране на група клиенти за продукт/кампания;
- сегментация на клиенти;
- автоматична класификация на текст/документи.
Тези технологии стават все по достъпни, бързи и интелигентни и могат лесно да се интегрират в корпоративна среда, уеб сайт или мобилно приложение.
Но стига с теорията. За конкретния пример, който ще разгледаме – класификация на текст – за обучение ще използваме база данни с по около 1000 съобщения от 20 различни новинарски групи (newsgroups) с определена тематика – автомобили, медицина, космос, религия и т.н. Данните са подготвени като таблица с две колони (Category и Text) и могат да се качат в Azure Machine Learning studio много лесно чрез използване на CSV/TSV файл.
Първата стъпка е да отворим Azure Machine Learning Studio (https://studio.azureml.net) и да създадем т.нар. Training Experiment, в който ще обучим избрания алгоритъм с предварително подготвената база данни и ще оценим колко добре се справя с предсказването. Ето как изглежда нашия примерен експеримент:
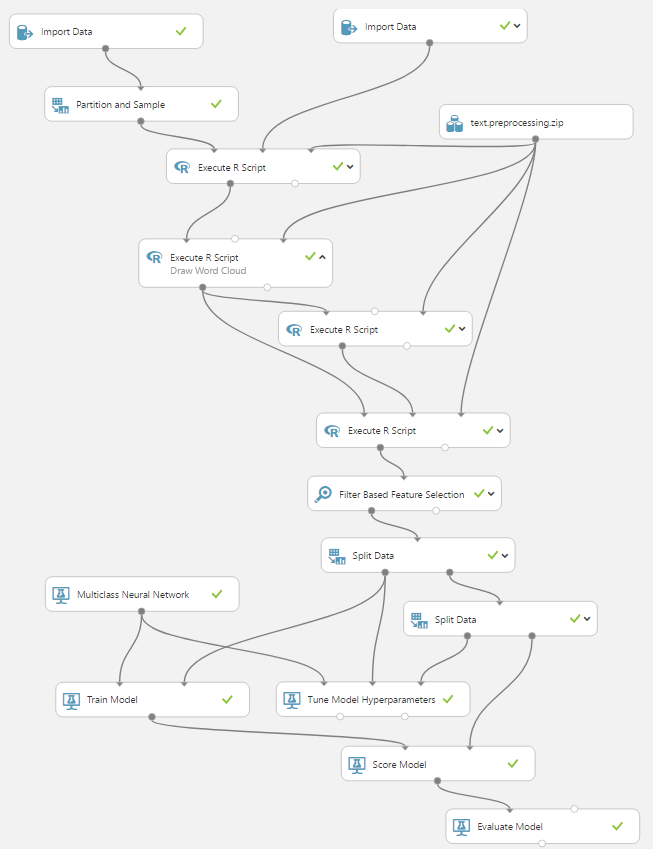
За по-любопитните експериментът е публикуван в Azure Machine Learning галерията: https://gallery.cortanaintelligence.com/Experiment/Doc-Classification, откъдето може да го използвате като шаблон и да създадете свои собствени модели на негова база.
Накратко експериментът се състои от следните стъпки:
- Зареждат се данните за обучение (категория, текст).
- Зарежда се речник с думи, които да бъдат изключени от модела – често срещани думи като “the”, “this”, “and”, “you”, и т.н.
- Зарежда се пакет с няколко скрипт модула на R – предоставен от Microsoft
- Първият R скрипт премахва думите от заредения речник, като допълнително подготвя текстовете за постигане на по-добри резултати – заменя главните букви, специални символи, премахва представки/наставки и т.н.
- Вторият R скрипт изчертава т.нар. word cloud, чрез който можем да визуализираме честотата на срещане да думите (пропорционално на размера) в различните категории:



- Третият R скрипт създава речник на думите с най-голяма тежест като отношение на честота на срещане в даден казус (document frequency, df), спрямо общата честота на срещане във всички казуси (idf):
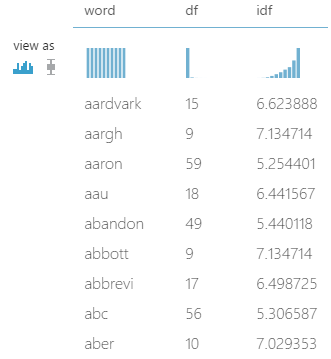
- Четвъртият R скрипт трансформира думите от създадения речник в колони – като в конкретния пример в последствие те са ограничени до топ 5000. В крайна сметка от първоначалната таблица с две колони – категория и текст (в която има около 20000 реда), създаваме такава с 5001 колони – категория и 5000 ключови думи, която подаваме към модела. Таблицата има 20 реда (по един за категория) и съдържа изчислените тегловни коефициенти за всяка ключова дума във всяка категория:

- Следва разделяне на данните, така че да имаме 70% от данните за обучение на модела, а останалите 30% разделяме по равно за оптимизиране на параметрите на алгоритъма и за проверка и оценка на това колко точно се справя той.
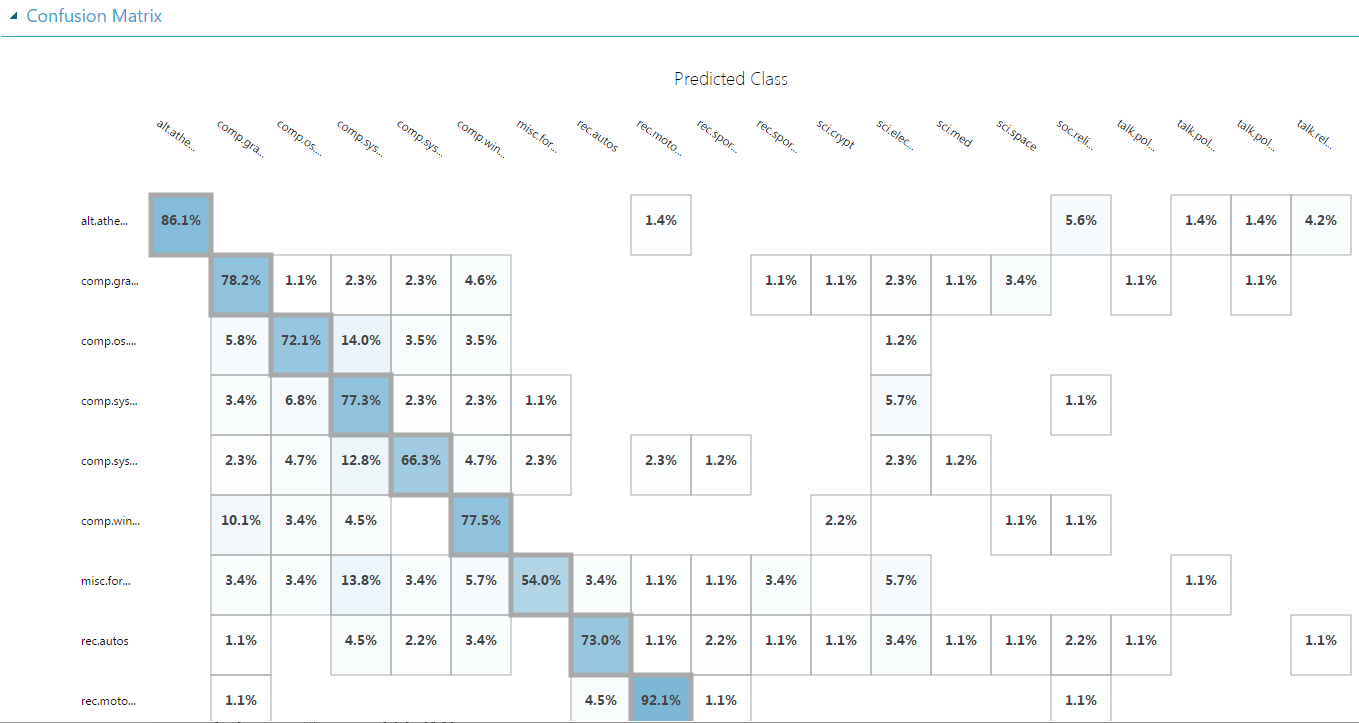
В случая използваме Multiclass Neural Network и като цяло получаваме доста добра точност – над 80 %. В следната матрица можем да видим как са класифицирани 15% от данните за оценка на модела в отделните категории след обучението. Идеалният модел би класифицирал 100% от данните по удебеления диагонал на матрицата:
Така обученият модел се конвертира в Predictive Experiment и съответно се публикува като уеб услуга за директно използване. За нагледна демонстрация съм направил простичко тестово приложение, което всеки може да свали и използва, за да се свърже на живо с уеб услугите на модела и да провери доколко добре се справя той с класификацията на английски текст. Опитайте сами!
Връзка за сваляне на примерното приложение можете да намерите тук: Свали AMLDocClass
Стартирайте AMLDocClass.exe от прикачения zip файл. Поставете английски текст и натиснете бутона Classify. Необходимо е да имате връзка с Интернет.
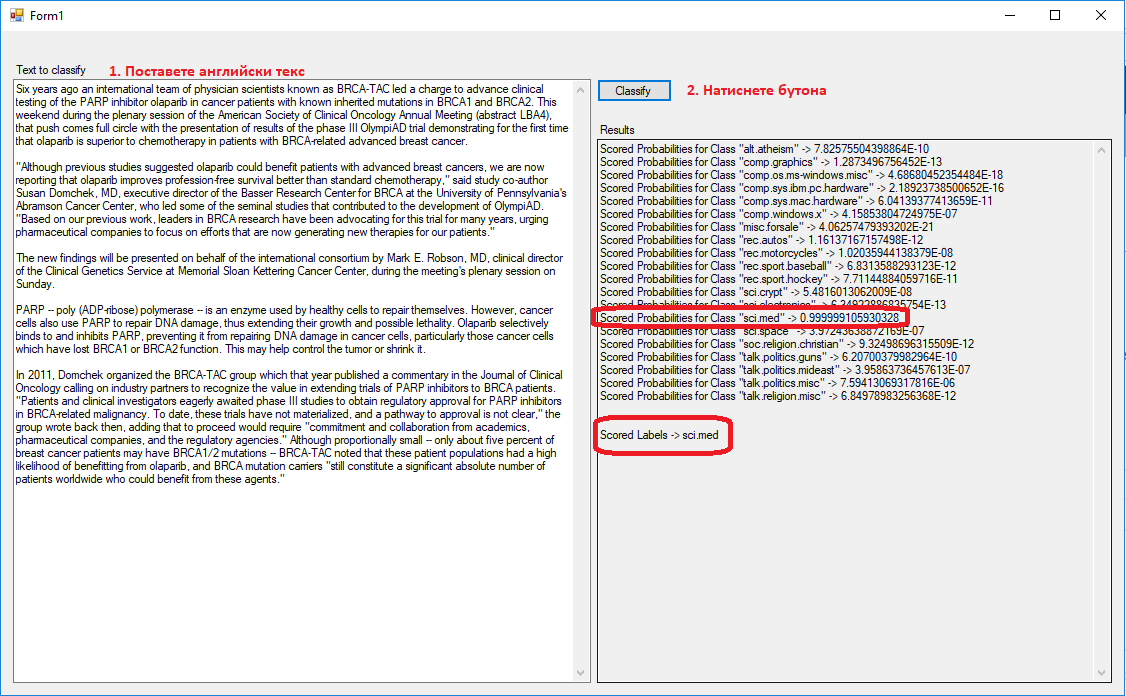
Като резултат, моделът връща вероятностите за всяка една категория и категорията, която е избрана с най-висока вероятност (Scored) – в конкретния случай това е sci.med (наука – медицина). Вероятностите са в границите 0-1, като дадените числа завършващи на E-XX са незначително малки и са дадени като отрицателна степен на 10 – например 7.82575504398864E-10.
В следващата статия ще разгледаме още една вълнуваща технология – Azure Cognitive Services – с възможности за висши когнитивни функции като разпознаване на изображения, лица, емоции, реч, команди и др.
Източници и полезни връзки
Data Mining with Microsoft SQL Server (Jamie MacLennan, ZhaoHui Tang, Bogdan Crivat)
Hands-On Programming with R (Garrett Grolemund)
Повече информация за класовете задачи и избор на оптимален алгоритъм: https://docs.microsoft.com/en-us/azure/machine-learning/machine-learning-algorithm-cheat-sheet
Подробни стъпки за създаване на експеримент за класификация на текст: https://blogs.technet.microsoft.com/machinelearning/2015/05/06/azure-ml-text-classification-template/
А втор: Николай Ефтимов
втор: Николай Ефтимов
Архитект „Бизнес приложения“